이번에 한이음에서 주최하는 ICT멘토링 MS AI머신러닝(기초)교육에 참여하게 되었다. 토일 10:00 ~ 18:00까지 2일에 걸쳐서 진행되는데 첫째 날에는 인공지능 개론/사례, 머신러닝 이론, Classification모델에 대해서 배웠다. 이번 포스팅에서는 첫째 날 배운 내용에 대해 리뷰해보도록 하겠다.
인공지능이란?
기계를 인간과 비슷하게 동작하게 하는 기술이다. 인간이 사고하는 과정처럼 인식(보고, 듣고) -> 이해(학습, 분석) -> 반응(결과)의 순으로 진행이된다.
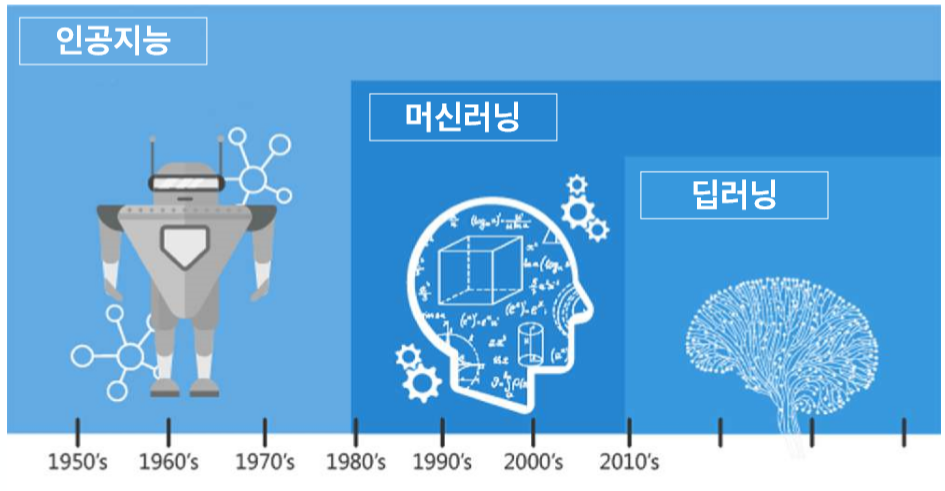
인공지능 : 기계 혹은 컴퓨터가 인간의 지능을 모방해 인간과 비슷하게 동작하도록 만들어진 기술
머신러닝 : 인공지능의 한 분야. 컴퓨터가 데이터를 이용해 학습하는 알고리즘 기술(input 과 output을 보고 중간에 어떤 일이 일어나는지 파악하는 것)
ex) 인공신경망, 결정 트리, 벡터 머신 등딥러닝 : 인공신경망을 사용하는 머신러닝 모델링 방법 중 하나(Neural Network)
다층 인공신경망 구조를 사용하여 빅 데이터 학습
ex) 사물인식, 감정분석, 필기체 인식, 음성인식 등
머신러닝의 종류
머신러닝은 크게 3가지로 분류를 할 수 있다.
Supervised Learning(지도학습, 감독학습)
- 문제와 함께 정답을 제공(Feature & Label)
- 예측(Regression), 추정(Forecast), 분류(Classification) 등의 문제 해결 시 주로 사용
- 만들기 쉽고, 성능도 좋음
Unsupervised Learning (비지도학습)
- 문제만 제공 (Feature)
- 패턴/구조 발견 (Anomaly Detection) : 평소와 다른 점 발견 (이상감지) ex) 지진, 의료 등 이상 징후 감지
- 그룹화 (Clustering) : 여러 데이터를 input, 알아서 비슷한 것들을 모아줌
Reinforcement Learning (강화 학습)
- 정답이 아닌 보상 제공
- 인과관계가 중요
- 게임(알파고), 로봇
- 사람의 움직임을 따라 움직이는 아바타
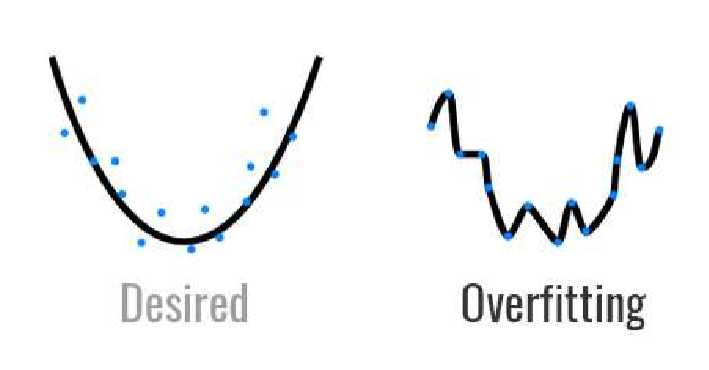
Overfitting(과적합)
Overfitting은 학습이 너무 잘 되어서 학습데이터에 대해서는 높은 정확도를 나타내지만 테스트 데이터나 실제 적용시에는 성능이 떨어지는 현상을 말한다.
머신러닝의 workflow
일반적인 머신러닝의 작업순서는 다음과 같다.
- 문제 정의
- 데이터 셋 준비(전처리)
- 모델 설정
- 모델 훈련 / 평가
- 모델 활용
먼저 해결해야할 문제를 정의한다. 그리고 그에 필요한 데이터 셋을 수집하고 학습시키기 위해 전처리 과정을 거친다. 이후 적합한 알고리즘을 선택하여 모델을 설정하고 데이터 셋을 학습 데이터와 테스트 데이터로 나누어 훈련을 시키고 테스트를 하여 훈련이 잘 되었다면 모델을 이용하여 필요한 곳에 사용하면 된다.
실습
첫째 날의 실습 환경은 MS의 클라우드 서비스인 Azure를 사용한 Azure ML Studio를 사용했다.
Azure ML Studio는 코드를 따로 작성하지 않고 머신러닝의 각 과정을 모듈화하고 데이터 시각화 또한 잘 되어있어 처음 머신러닝을 배울 때 쉽게 이해할 수 있다.
실습해보았던 문제는 타이타닉 탑승객의 데이터 셋을 이용하여 생존 여부를 예측하는 것이다. 탑승객이 살았거나 죽었거나의 두가지로 나누어지므로 2진 분류 문제이고 Supervised Learning에 Classification에 속한다.
진행과정은 다음과 같다.
Data Processing
Feature Selection – Feature Metadata Edit – Clean Missing data – data split
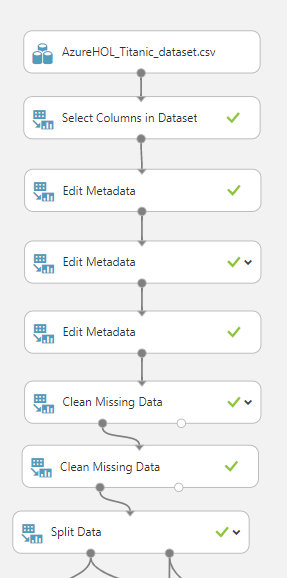
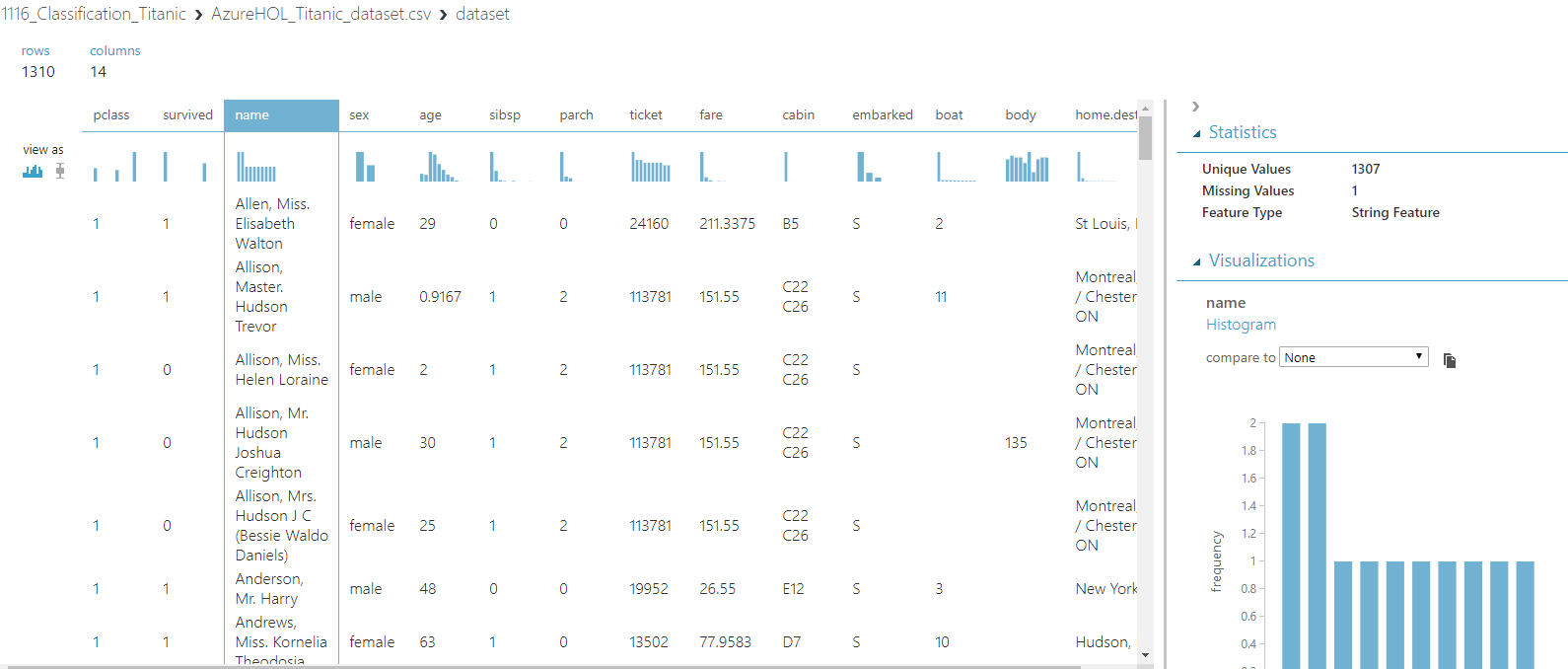
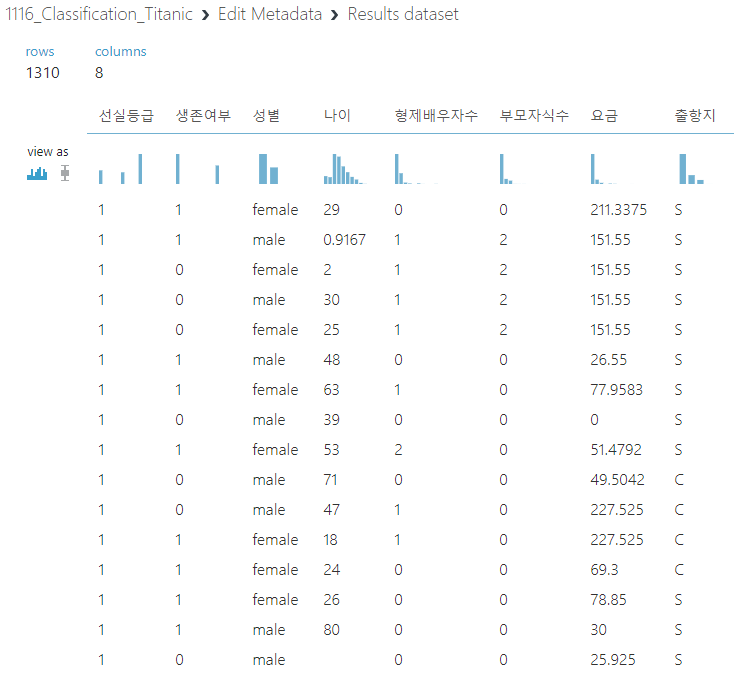
위와 그림은 관계가 없다고 생각하는 데이터들을 제외하고 남은 데이터들이다.
이후 각 데이터 별로 지정된 값만 입력을 받을 데이터에는 Make Categorical을 적용해주고 생존 여부 같은 경우는 데이터 타입을 boolean타입으로 변경하고 label로 지정을 해준다.
다음은 Clean Missing data 과정인데 Missing Data를 삭제하거나 다른 데이터로 대체하여 학습을 수행하도록 하는 과정이다. 이 과정에서는 탑승객의 나이같은 경우는 평균값으로 데이터를 채워주고 성별 같은 숫자형이 아닌 데이터들은 가장 많은 빈도를 가지는 데이터로 대체하여 채워주었다.
다음 Data Split과정은 데이터 셋을 약 780%의 비율은 Training Data Set로 나머지 230%는 Test Data Set로 나누어 학습시키게 된다. 이 때, Random Split을 해주어야 하는데 만약 데이터가 정렬되어 있는 경우 아래쪽의 30%를 테스트 데이터로 사용한다면 정확한 결과를 얻기 힘들기 때문에 random seed를 적용하여 랜덤한 테스트 셋을 추출하게 된다. 또한 이 과정에서 Stratified Split도 적용하였는데 Startified Split란 예를 들어 성별에 적용한다면 18명 중 6명을 추출하는 경우 일반적으로는 남여 관계없이 6명을 선택하지만 이 경우 남자 3명 여자 3명을 추출하는 식으로 치우치지 않은 테스트 셋을 추출할 수 있게 된다.
Train Model
Initialize - Train Model - Score Model - Evaluate - Deploy
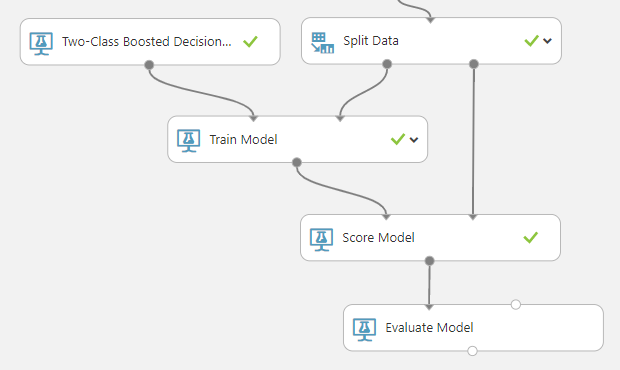
모델을 학습시키는 단계에서는 먼저 어떠한 알고리즘으로 학습을 시킬지 생각해야 한다. 알고리즘의 선택 기준으로는 정확도(Accuracy), 훈련 시간(Train Time), 선형성(Linearity), Parameter, Feature 등이 있다. 여러가지 요소를 잘 고려하여 선택해야 한다.
여기서는 2진 분류 알고리즘 중 하나인 Two-Class Boosted Decision Tree라는 모델을 사용하여 학습을 시켰다. 아래는 Training set을 이용하여 학습을 시키고 Score Model 단계에서 Test set으로 테스트를 한 결과이다.
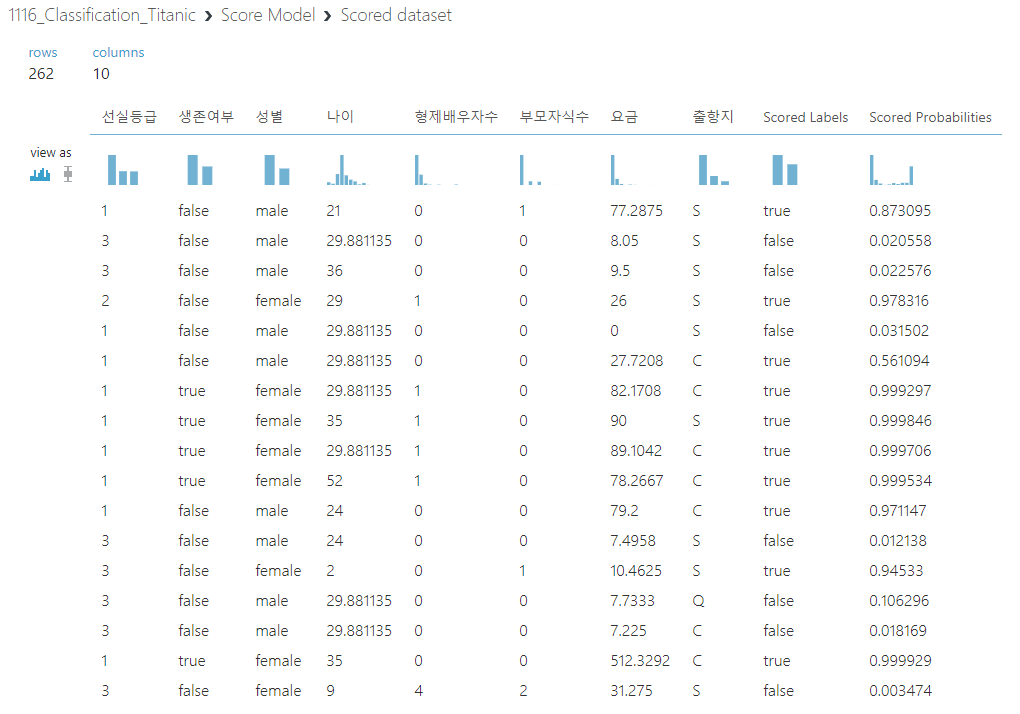
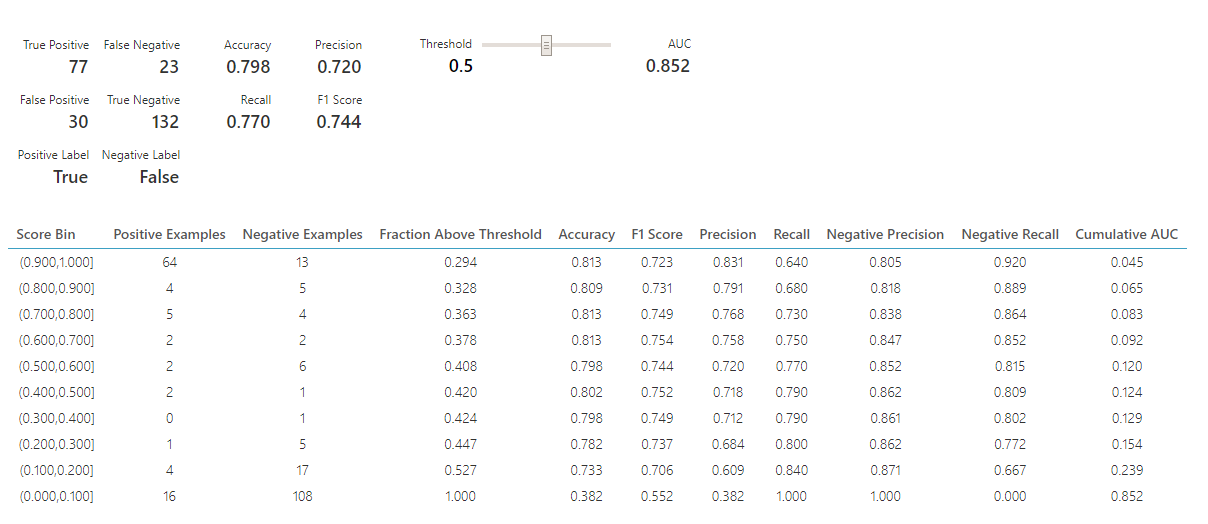
마지막으로 Evaluate Model 단계인데 학습된 모델이 얼마나 정확하게 Test set을 맞추었는지 평가할 수 있다. 보통 Accuracy를 가장 중요하게 보면 되는데 각각의 값들은 아래의 식을 따른다.
Accuracy : TP + TN / TP+ FP +FN + TN
Precision : TP / TP + FP
Recall : TP / TP + FN
어느 분야에 활용되느냐에 따라 중요하게 보아야 할 값이 달라지게 된다.