이번에는 둘째 날에 배웠던 내용에 대해 리뷰해보도록 하겠다. 둘째 날은 Regression모델, 머신러닝 알고리즘, python라이브러리인 scikit-learn을 이용하여 실습을 진행하였다.
오전에는 어제 했던 Classification모델에 이어서 Azure ML Studio에서 Regression모델을 실습해보았다.
Regression모델 같은 경우는 위와 같이 x값에 따른 y의 값을 찾고 싶을 때 사용한다.
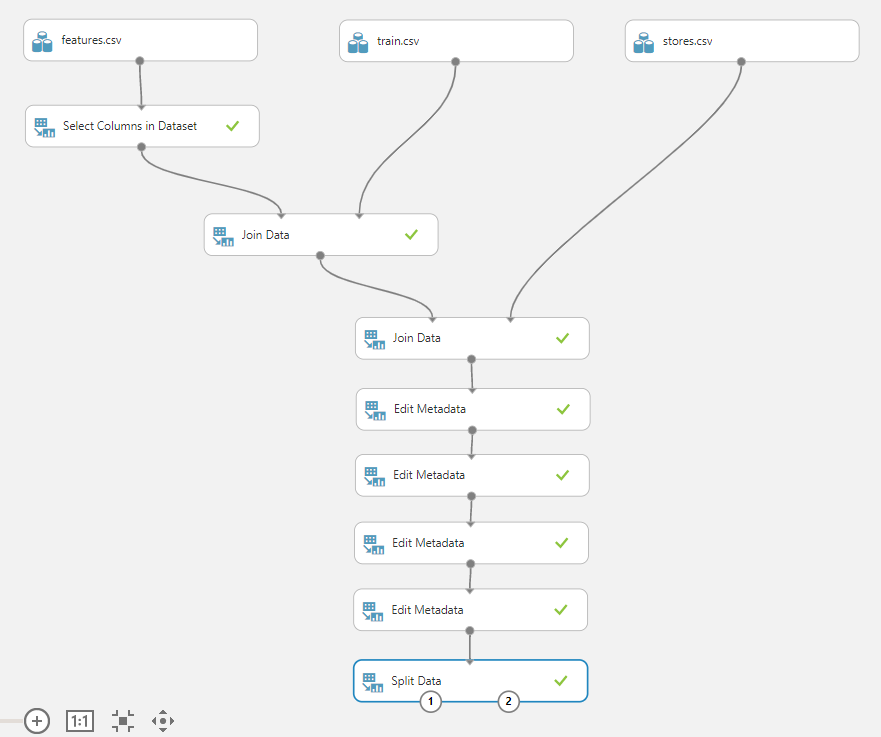
데이터 셋으로는 예전에 Kaggle에서 올라왔던 월마트 판매량 예측을 위한 데이터 셋을 이용하였다. 이 데이터는 어제 사용했던 것들과는 달리 3개의 데이터 셋이 따로 존재해서 이 세개의 데이터를 합치는 과정이 필요하다.
먼저 featrue.csv파일을 select columns in datset에서 필요하지 않은 컬럼을 제외시키고 train.csv파일을 가져와 join data로 합쳐주었다. 이 때, 지점과 날짜를 키값으로 하여 합쳤고 다시 stores.csv파일까지 Join Data로 지점을 키값으로 하여 합쳤다.
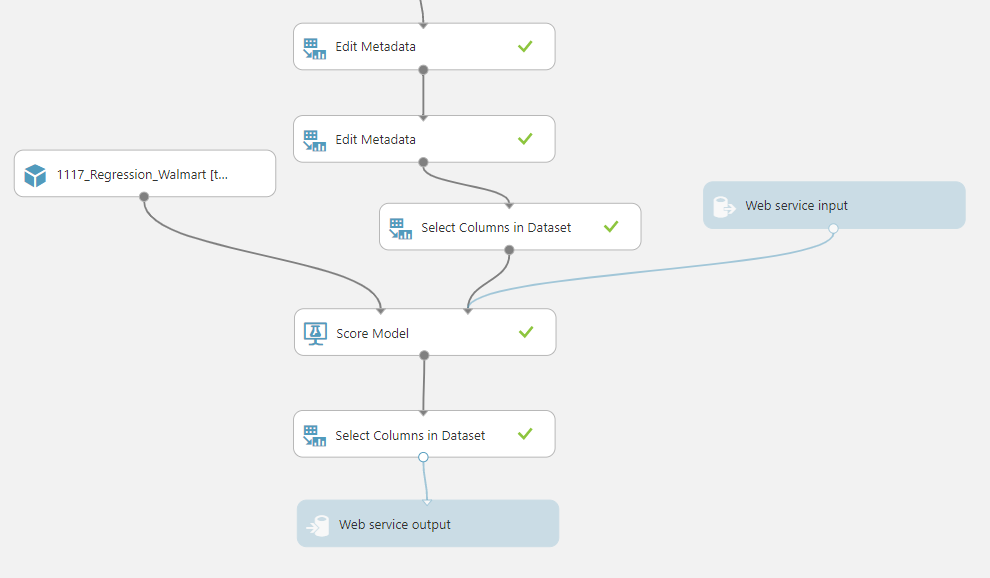
이후 Edit Metadata에서 숫자데이터이지만 string형으로 저장되어 있는 CPI, Unemployment를 float형으로 변환해주었다. 다음으로 예측하고 싶은 데이터인 Weekly Sales(주간판매량)을 레이블로 설정해주고 지점, 부서, 유형을 make categorical해주었다. (다른 데이터를 입력받지 않을 것이고, 상하관계가 없으므로)
이제 데이터 전처리가 끝났으므로 모델을 선택하여 학습을 시켜준다.
Linear Regression이라는 알고리즘을 사용하여 학습시켜보았다.
위의 이미지과 같이 Scored Labels는 예측 데이터이고 주간 판매량이 실제 데이터이다.
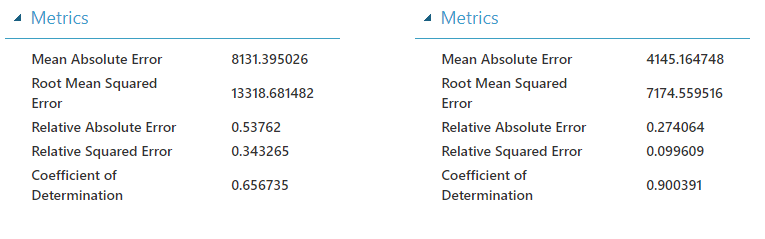
아래 이미지는 Boosted Decision Tree Regression알고리즘을 사용하여 한번 더 예측하고 Linear Regression와 비교해본 것이다. 왼쪽이 Linear Regression이고 오른쪽이 Boosted Decision Tree Regression이다.
위의 데이터를 보면 여러가지 값들이 있는데 여기서 주요하게 보아야 할 값은 Mean Absolute Error와 Root Mean Squared Error를 보면 된다. 둘다 예측 값과 실측 값의 차이를 나타내는데 Mean Absolute Error는 절대값을 취한 후 평균을 내어주고 Mean Squared Error는 먼저 제곱을 한 값으로 평균을 낸 후에 루트를 씌워준다. 이게 어떤 차이가 있냐면 Mean Squared Error는 잘못 예측하여 크게 차이나는 값들이 있나면 값이 크게 나타난다. 이 말은 Mean Squared Error가 크게 나타난다면 예측 값 중 크게 차이나는 값들이 존재한다는 것이다. 이 두 값이 낮게 나타나야 좋은 모델이라고 할 수 있다.
Relative Absolute Error는 예측 값과 실제 값의 비율로 같은 단위로 나누어 상대적 비교가 가능하다. 이를 통해 다른 모델들 과도 비교가 가능하게 되며 이 값은 0에 가까울 수록 좋다. Coefficient of Determination는 1에 가까울 수록 정확도가 높다고 보면 된다.
위의 데이터를 비교해보면 오른쪽의 데이터가 훨씬 잘 예측을 한 것을 알 수 있다. 따라서 우측의 알고리즘을 웹 서버로 배포를 해보겠다.
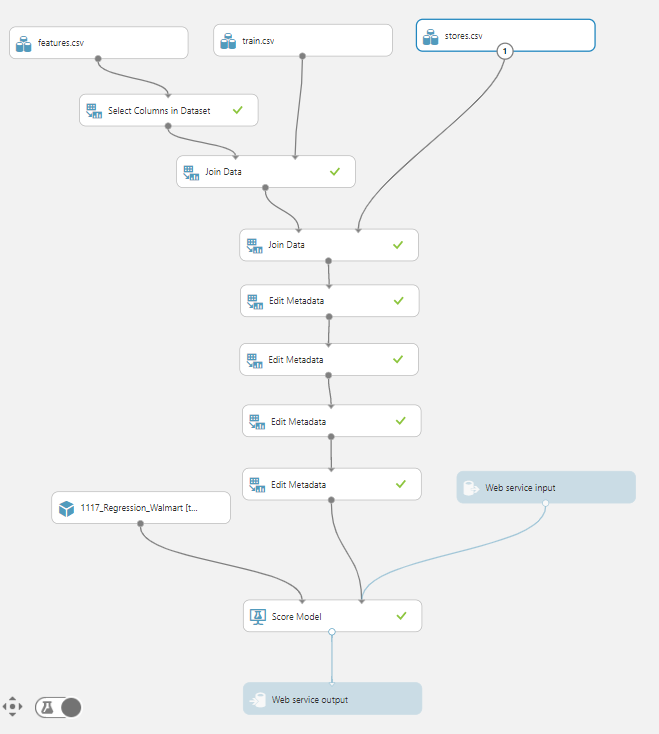
이제 Set Up Web Service에서 Update Predictive Experiment를 눌러 아래와 같이 설정해준다.
이때 배포 후에 입력을 받을 때에 구하는 결과값인 주간판매량은 입력을 받을 필요가 없고, 리턴받을 때 입력했던 값들은 받지 않아도 되므로 Scored Labels만 선택하여 준다.
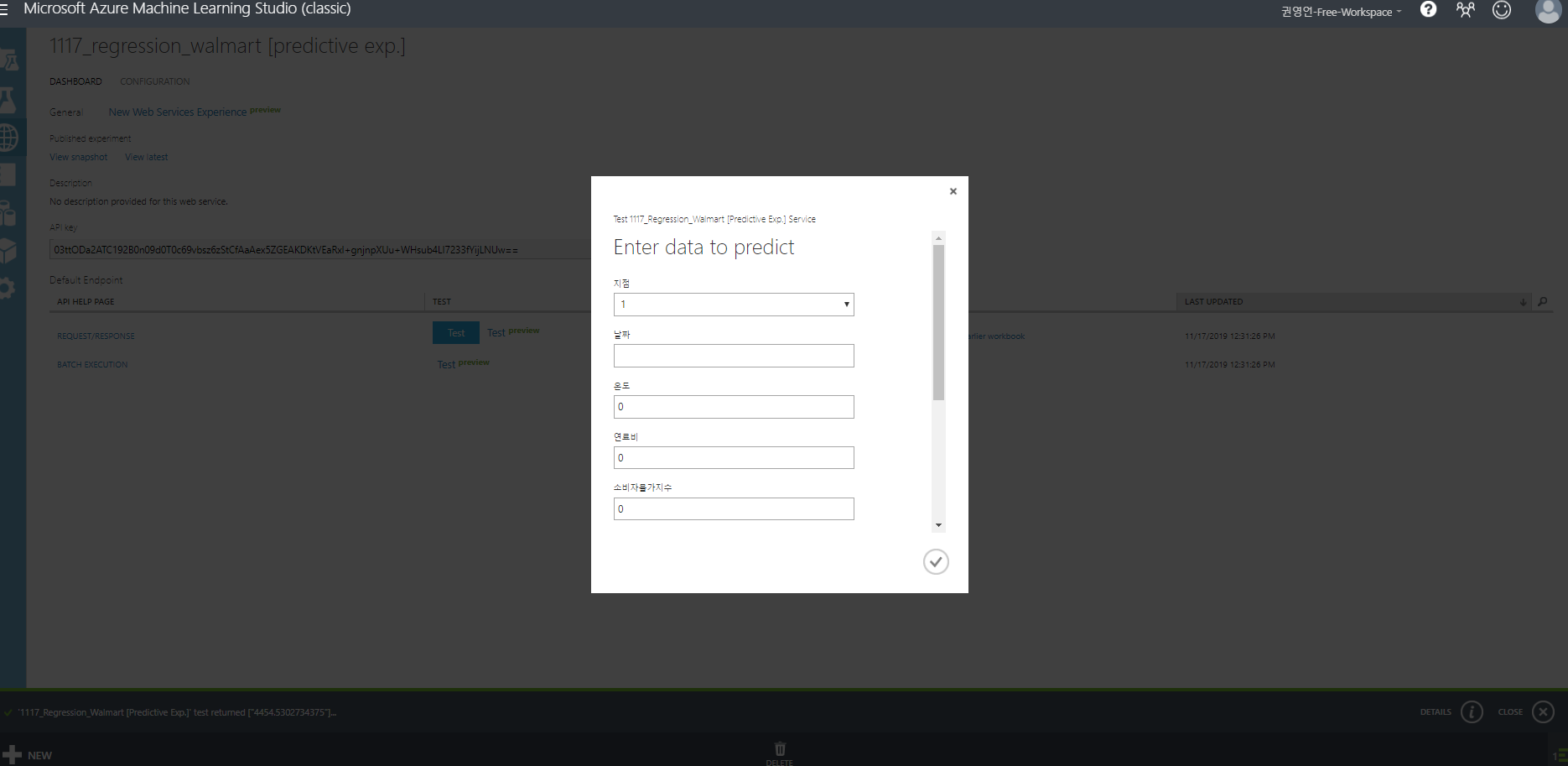
이후 RUN 이후에 Deploy Web Service 버튼을 눌러준다. 여기까지 되었다면 이제 임의의 값을 입력하여 테스트를 해볼 수 있다.
위와 같이 넘어간 화면에서 테스트 버튼을 눌러보면 다음과 같은 화면이 나타나는데 여기서 입력 값들을 입력해주면 결과를 확인할 수 있다.
이제 서버에 배포된 모델을 파이썬 개발환경인 주피터 노트북에서 이용해보자.
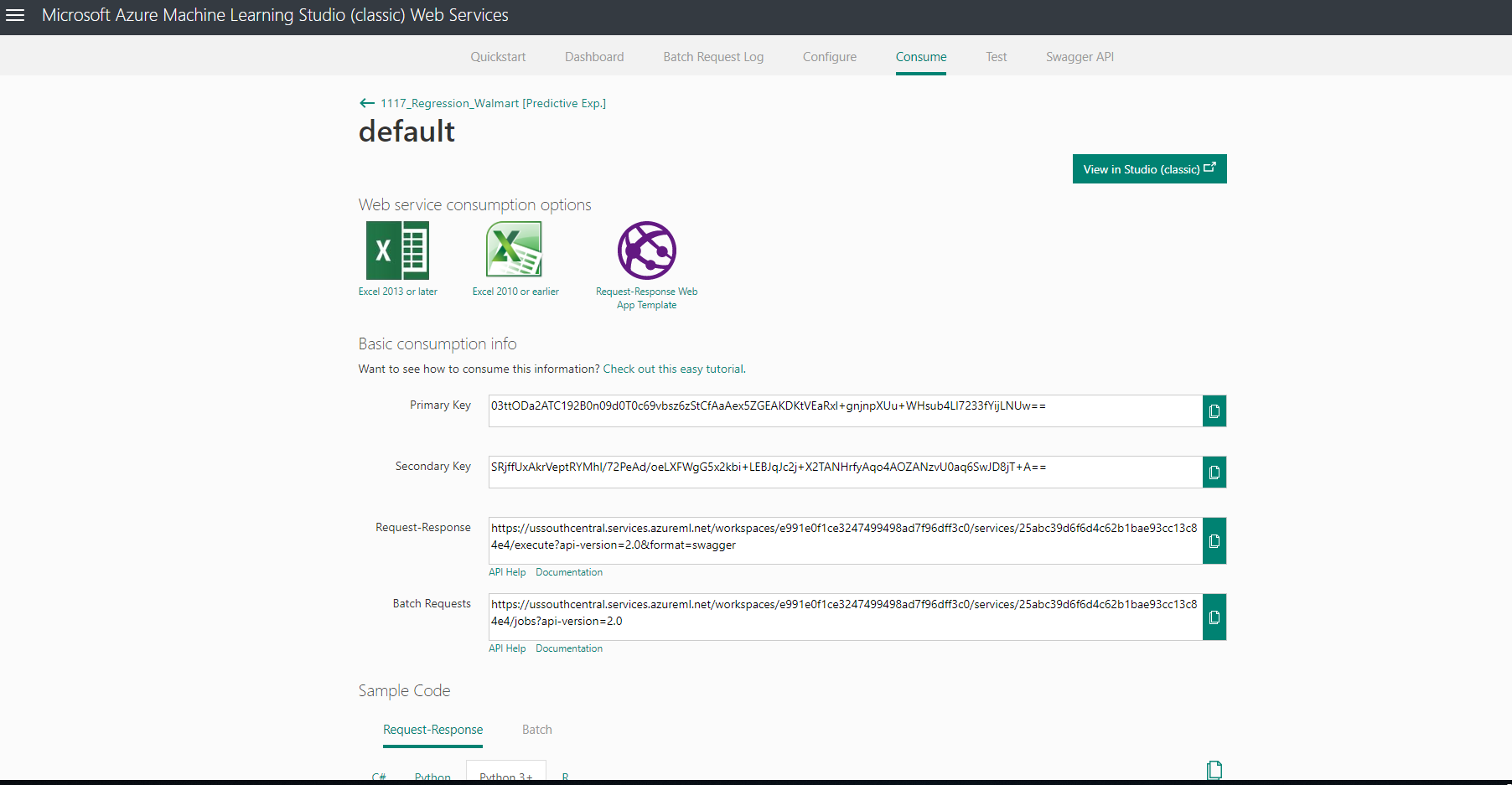
위의 화면에서 New Web Services Experience 버튼을 누르면 아래와 같이 넘어간다. 표시된 부분 중 api key는 이후에 사용될 부분이다.
이 화면으로 넘어오게 되면 Use endpoint를 눌러준다.
이제 위와 같은 화면으로 넘어오게 되는데 아래로 내려보면
위와 같이 Sample Code에서 원하는 언어를 선택하여 가져다가 사용할 수 있다. 우리는 python3으로 주피터 노트북에 옮겨 사용해보았다.
url = 'https://ussouthcentral.services.azureml.net/workspaces/e991e0f1ce3247499498ad7f96dff3c0/services/25abc39d6f6d4c62b1bae93cc13c84e4/execute?api-version=2.0&format=swagger' api_key = '03ttODa2ATC192B0n09d0T0c69vbsz6zStCfAaAex5ZGEAKDKtVEaRxl+gnjnpXUu+WHsub4LI7233fYijLNUw=='# Replace this with the API key for the web service headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}
req = urllib.request.Request(url, body, headers)
try: response = urllib.request.urlopen(req)
result = response.read() print(result) except urllib.error.HTTPError as error: print("The request failed with status code: " + str(error.code))
# Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure print(error.info()) print(json.loads(error.read().decode("utf8", 'ignore')))
결과 : b’{“Results”:{“output1”:[{“Scored Labels”:”8219.6923828125”}]}}’
위와 같은 코드가 나오게되고 먼저 위에서 표시했던 api key를 apikey=”” << 에 넣어주고 원하는 입력 데이터를 입력한 후 실행을 하게 되면 해당되는 데이터의 예측 값이 리턴되어 출력된다. 이러한 마트 매출액 예측을 이용하면 다음날 매출을 예측하고 예측 데이터가 평소 매출보다 높게 나온다면 직원을 더 출근시키고, 예측 데이터가 적게 나온다면 할인 메시지를 고객들에게 보내는 것 등의 작업이 가능하게 된다.
어제 만들었던 타이타닉 생존 예측 데이터 또한 위와 같은 과정으로 배포하여보았고 샘플 코드는 아래와 같다.
url = 'https://ussouthcentral.services.azureml.net/workspaces/e991e0f1ce3247499498ad7f96dff3c0/services/89edc6fde21540199e28af74c15a5a6a/execute?api-version=2.0&format=swagger' api_key = 'aPRcbktBs1ZePedj32JOzkGN2H9BIVC9NTuOPKokhtHpgMTc22QQHpUha7QPSHkFdB+wnPnxwdSRpKPd2o/nHQ=='# Replace this with the API key for the web service headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}
req = urllib.request.Request(url, body, headers)
try: response = urllib.request.urlopen(req)
result = response.read() print(result) except urllib.error.HTTPError as error: print("The request failed with status code: " + str(error.code))
# Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure print(error.info()) print(json.loads(error.read().decode("utf8", 'ignore')))
결과 : b’{“Results”:{“output1”:[{“Scored Labels”:”True”,”Scored Probabilities”:”0.827437460422516”}]}}’
이렇게 ML Studio에서 머신러닝을 수행하면 그 모델을 api화 하여 쉽게 배포하고 활용할 수 있다는 것이 정말 신기했다.
다음은 파이썬으로 직접 코드를 작성하여 머신러닝을 수행해 보았다.
첫번째는 간단히 10개의 데이터로 연습하였다. 국가와 나이, 경력, 급여의 컬럼을 가진 데이터이고 국가, 나이, 경력을 feature로 하며 급여를 label로 급여를 예측하는 Regression모델이다.
2019.11.17. 머신러닝 Regression with python3.6
1
!pip install --upgrade pandas==0.24.0
1 2 3 4 5 6
# 0. Package 가져오기 import pandas as pd import numpy as np
print(pd.__version__) print(np.__version__)
0.24.0
1.17.0
1 2 3
# 1. CSV 데이터 가져오기 data = pd.read_csv('SR_Data.csv') # 데이터 읽어오기 data.head(10) # 데이터 앞 10개 출력
Country
Age
Year
Salary
0
France
44.0
15.0
72000
1
Spain
27.0
3.0
48000
2
Germany
30.0
2.0
54000
3
Spain
38.0
NaN
61000
4
Germany
40.0
10.0
61000
5
France
35.0
NaN
58000
6
Spain
NaN
6.0
52000
7
France
48.0
NaN
79000
8
Germany
50.0
21.0
83000
9
France
37.0
7.0
67000
1 2 3 4 5 6 7 8 9
# 2. feature/label 나누기 # X = data[['Country', 'Age', 'Year']].to_numpy() # Feature : pandas형태를 numpy형태로 변환 # y = data['Salary'].to_numpy # Label : pandas형태를 numpy형태로 변환
# 대부분 다 아래쳐럼 사용 X = data.iloc[:, :-1].to_numpy() # Feature - index location 보통 label이 맨 끝에 있기 때문 (이렇게 많이 사용) y = data.iloc[:, -1].to_numpy() # Label - 마지막 열을 가져옴 print(X) print(y)
imputer.fit(x) x = imputer.transform(x) # 위의 과정을 한번에 처리 (같은 데이터라면 한번에 가능) x = imputer.fit_transform(x)
1
print(X[:, 1:])
1 2 3 4 5 6 7 8 9 10
# 4. Make Categorical from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer from sklearn.preprocessing import LabelEncoder
lebelEncoder = LabelEncoder() X[:, 0] = lebelEncoder.fit_transform(X[:, 0]) print(X) # 여기까지만 수행하면 컴퓨터가 0 1 2 순으로 순위를 매겨서 학습함 # 하지만 국가간에 상하관계는 없으므로 아래 과정을 거쳐야함
onehotEncoder = OneHotEncoder(categorical_features=[0]) X = onehotEncoder.fit_transform(X).toarray() print(X)
[[ 1. 0. 1. 0. 0. 44.
15. ]
[ 0. 1. 0. 0. 1. 27.
3. ]
[ 0. 1. 0. 1. 0. 30.
2. ]
[ 0. 1. 0. 0. 1. 38.
9.14285714]
[ 0. 1. 0. 1. 0. 40.
10. ]
[ 1. 0. 1. 0. 0. 35.
9.14285714]
[ 0. 1. 0. 0. 1. 38.77777778
6. ]
[ 1. 0. 1. 0. 0. 48.
9.14285714]
[ 0. 1. 0. 1. 0. 50.
21. ]
[ 1. 0. 1. 0. 0. 37.
7. ]]
c:\users\kyu93\appdata\local\programs\python\python37\lib\site-packages\sklearn\preprocessing\_encoders.py:415: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values.
If you want the future behaviour and silence this warning, you can specify "categories='auto'".
In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly.
warnings.warn(msg, FutureWarning)
c:\users\kyu93\appdata\local\programs\python\python37\lib\site-packages\sklearn\preprocessing\_encoders.py:451: DeprecationWarning: The 'categorical_features' keyword is deprecated in version 0.20 and will be removed in 0.22. You can use the ColumnTransformer instead.
"use the ColumnTransformer instead.", DeprecationWarning)
1 2 3 4 5 6 7
# 4. Make Categorical
# 지금은 이렇게 사용해도 같은 과정임 한번에 가능 from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer
# 6. Standardization # 스케일링 작업 MinMaxScaler : 최소 0 최대 1로 변환, StandardScaler : 가장 많이 사용 # y는 어차피 값이 1개이므로 안해도 됨, train과 test는 따로 스케이링 해주어야함 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler()
c:\users\kyu93\appdata\local\programs\python\python37\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
이렇게 2일간의 ICT멘토링 머신러닝 기초교육이 마무리되었다. 내 주말을 모두 뺏겨버렸지만 아깝지 않게 많은 것을 얻어가는 것 같다. 기본적인 머신러닝의 이론부터 활용 분야, 알고리즘 등 몰랐거나 애매하게 알았던 부분을 제대로 알게 되었고 Azure ML Studio에서 실습을 통해 머신러닝의 workflow를 직접 경험해 볼 수 있었다. 배포까지 해보면서 실제로 머신러닝을 사용한다면 어떠한 방식으로 구현을 해야할 것 같다는 생각도 해볼 수 있었고 또한 파이썬으로 주피터에서 직접 코드도 작성해보며 ML Studio에서 진행했던 흐름을 실제 코드로는 어떻게 작성되는지도 보았다. 앞으로 계속해서 머신러닝을 공부할 것인데 그 기반을 잘 잡게된 것 같아 기분이 좋다. 다음주에 있는 딥러닝 교육도 참가해 리뷰해볼 예정이다.