저번주에 한이음에서 주최한 머신러닝 ICT멘토링 AI머신러닝(기초) 교육에 이어 이번에는 AI딥러닝 교육에 참가하게 되었다. 이번주도 토일 10:00 ~ 18:00까지 진행되는데 첫째 날은 딥러닝 이론, 케라스, Azure Cloud 설정, MLP 설정에 대해 배웠다.
딥러닝이란?
Deep Learning = Deep Neural Network = Artificial Neural Network(ANN) 인공 신경망
= Multi Layer Perceptron
인공신경망을 사용하는 머신러닝 모델링 방법 중 하나(Neural Network)이며 다층 인공신경망 구조를 사용하여 빅 데이터 학습한다.
perceptron
인공 신경망의 한 종류.
단층 퍼셉트론 은 다수의 신호(Input)을 받아서 하나의 신호(Output)를 출력한다. 이 동작은 뉴런과 아주 유사하고 그 과정은 다음과 같다. 다수의 입력을 받았을 때, 퍼셉트론은 각 입력 신호의 세기에 따라 다른 가중치를 부여한다. 그 결과를 고유한 방식으로 처리한 후, 입력 신호의 합이 일정 값을 초과한다면 그 결과를 다른 뉴련으로 전달한다.
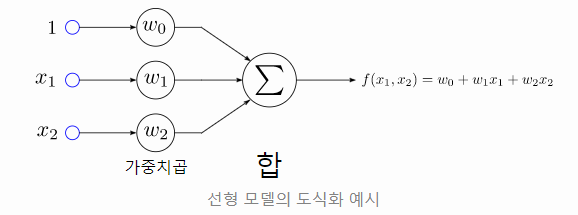
과거에는 이 퍼셉트론을 하드웨어를 이용하여 구현했다. 이 방식으로도 AND와 OR 문제를 해결이 가능했다. 그러나 이러한 단층 퍼셉트론으로는 XOR문제를 해결할 수 없었다.
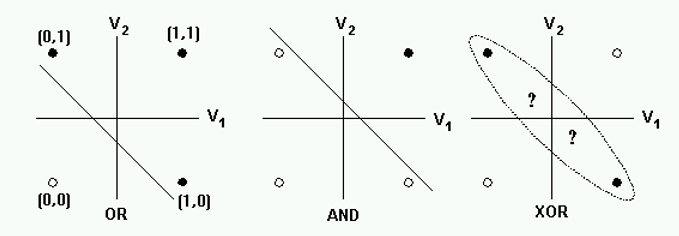
이러한 문제를 해결할 수 있는 것이 다층 퍼셉트론 이다.
딥러닝은 기본적으로 다음과 같은 순서로 진행이 된다.
Weight Initialization -> Forward Propagation -> Back Propagation
And Gate 연산을 예시로 퍼셉트론의 동작 순서에 대해 알아보자.
Weight Initialization (가중치 초기화) : 예를 들어 노드를 3개를 쌓는다면 입력 값마다 3개의 가중치가 생성된다. 아래의 예시에서는 And Gate에서의 동작을 예로 들었는데 여기서는 0과 1 두개의 노드가 존재하므로 각 입력 값마다 2개의 가중치를 생성하여 계산하였다.
Forward Propagation(순전파) : 가중치 초기화를 진행한 후에 각각의 입력 값과 가중치 값을 곱해주며 노드(퍼셉트론)에 들어온 값들을 모두 더해 activation function을 적용시켜 출력을 하게 된다. activation function은 threshold값을 지정해 그 값보다 크면 1, 작으면 0이 되는 식으로 동작할 수 있다.
Ex) And gate activation function(활성함수) : ex) [(0.5 < sum) : 1 / (0.5 > sum) : 0]
| w1 * x1 | w2 * x2 | sum | activate function | output | result | |
|---|---|---|---|---|---|---|
| [0, 0] | 0.7*0 | 0.4*0 | 0 | 0 | 0 | true |
| [1, 0] | 0.7*1 | 0.4*0 | 0.7 | 1 | 0 | false |
| [0, 1] | 0.7*0 | 0.4*1 | 0.4 | 0 | 0 | true |
| [1, 1] | 0.7*1 | 0.4*1 | 1.1 | 1 | 1 | true |
세번째 행 : 틀린 결과 -> Weight 재설정
Back Propagation(역전파) : 위의 표와 같이 activation function을 거쳐 나온 결과값과 실제 값과의 차이를 비교하여 값이 틀렸다면 다시 가중치를 재설정하여 Forward Propagation과정을 반복한다.
예측 값과 실제 값의 차이를 비교하는 과정으로 아래의 cost function이 사용된다.
- Cost function (=loss function = error function = objective function)
예측 값과 실제 값의 차이를 기반으로 모델의 정확도(성능)을 판단하기 위한 함수로 아래의 수식을 따른다.
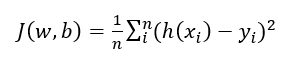
오차를 구하여 모델의 정확도를 판단하는데 이 값이 작을수록 모델의 성능이 좋다는 것을 뜻한다. 그래프로 본다면 아래와 같은데 이 오차를 줄이는 방법으로 경사하강법이 있다.
Gradient Descent(경사하강법)
해당 함수의 최소값 위치를 찾기 위해 비용함수(Cost Function)의 기울기가 (-)가 되는 방향으로 이동하여 최소값(=기울기 0)을 찾는 알고리즘이다.
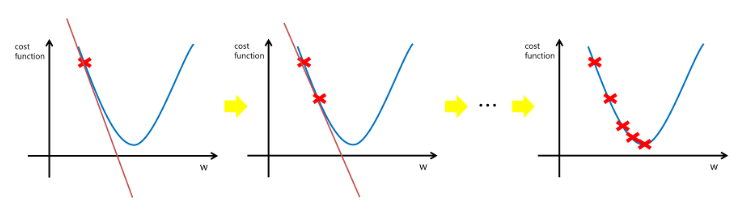
Optimizer(최적화기)
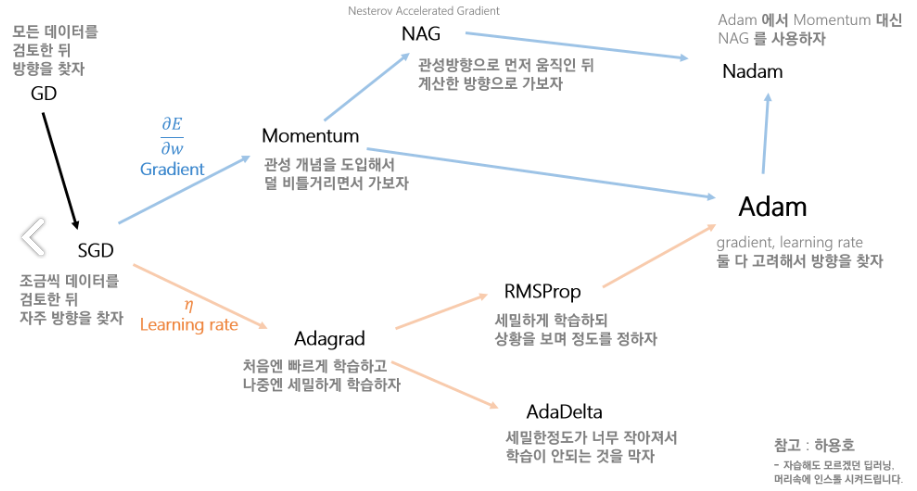
위에서 말한 최소값을 찾기 위한 방법으로 SGD, Momentum, NAG, Adagrad, Adadelta, Rmsprop, Adam 등의 여러가지 방법이 있는데, SGD는 layer가 늦은 경우 빠르게 찾아주고 데이터가 간단한 경우에 주로 사용한다. Adam은 정확도가 가장 높아서 일반적으로 가장 많이 사용한다고 한다.
optimizer의 발전과정
Vanishing Gradient
Vanishing Gradient Problem(기울기 값이 사라지는 문제)는 인공신경망을 기울기 값을 베이스로 하는 mothod(backpropagation)로 학습시키려고 할 때 발생하는 문제이다.
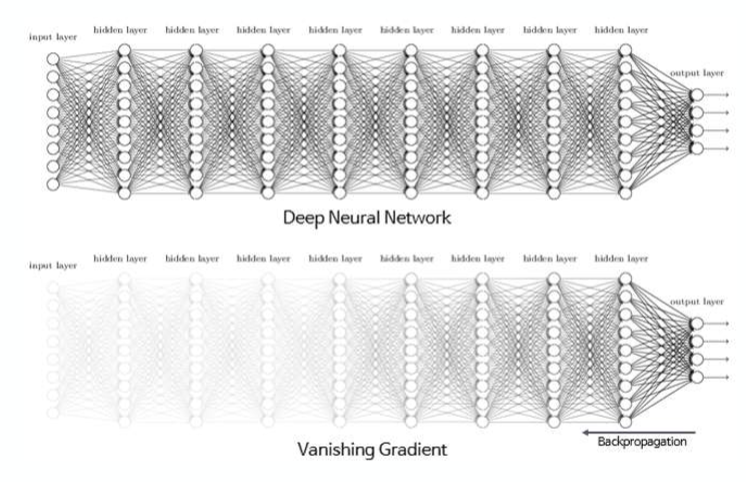
Vanishing Gradient Problem은 activate function을 의존적으로 일어난다. sigmoid함수나 tanh함수를 사용함으로써 발생하는 문제인데 layer가 깊어질수록 전달이 약해진다.
이 문제를 해결하기 위해서는 sigmoid함수 대신 ReLU 함수나 Leakey ReLU 등의 함수를 사용하면 된다.
Overfitting
저번 머신러닝 교육 내용에도 있었지만 역시 딥러닝에도 Overfitting이 존재한다. overfitting은 훈련 데이터에만 정확도가 높아져 새로운 데이터에는 성능이 떨어지는 현상을 말하는데 이를 위한 해결방안으로 다음과 같은 것들이 있다.
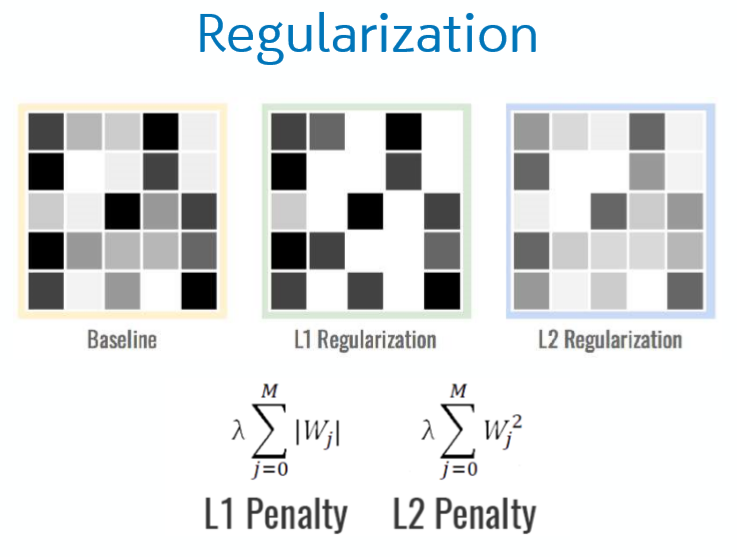
– L1 Regularization : 세세한 값들은 무시하고 큰 특징들만 추출
– L2 Regularization : 세부적인 값들을 약하게 해줌
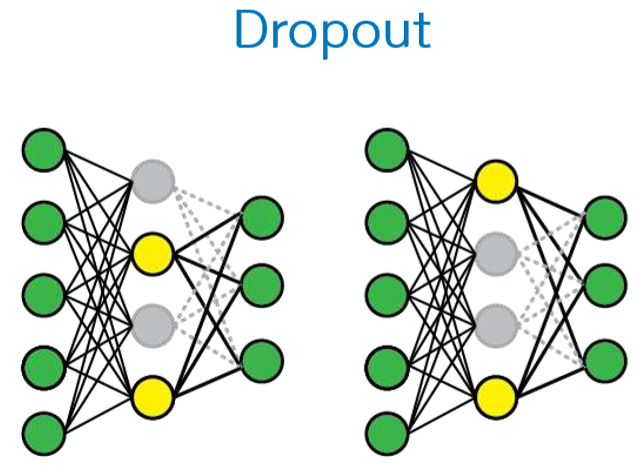
- – Dropout : hidden node 중 몇 개를 끊어 냄 -> 똑같은 것만 학습하는 것을 방지
- 성능이 좋고 많이 사용 (20~50% 노드를 꺼줌)
신경망 구조
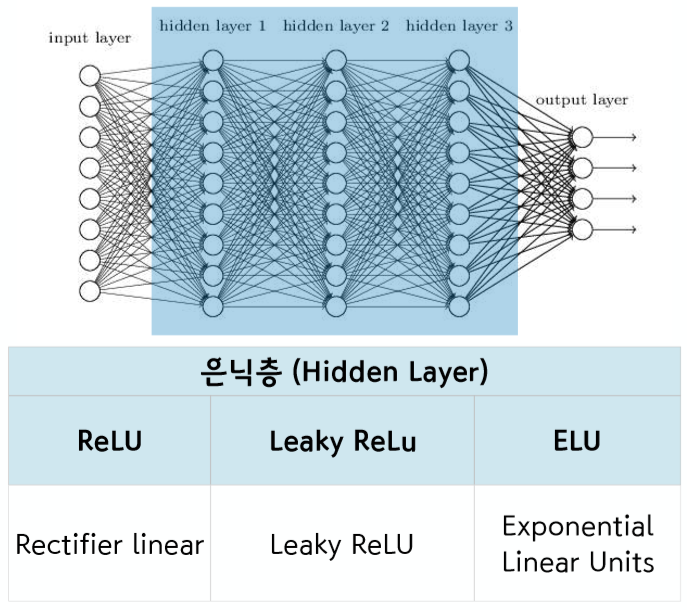
실습은 딥러닝 방식중 하나인 MLP 를 사용하였고 AND, XOR 기능을 수행하는 모델을 만들었고 마지막으로 당뇨병 예측 모델을 만들어보았다.
2019.11.23. 딥-러닝 과정 Mulit Layer Perceptron(MLP)
첫번째 실습. Simple Keras 모델 생성/학습 - AND Function
1 | # 1. Numpy 가져오기 |
1.17.01 | # 2. 입력/출력 데이터 만들기 |
[[0 0]
[1 0]
[0 1]
[1 1]]
[[0]
[0]
[0]
[1]]1 | # 3. Keras 패키지 가져오기 |
2.3.11 | # 4. MLP 모델 생성 |
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 4) 12
_________________________________________________________________
dense_2 (Dense) (None, 1) 5
=================================================================
Total params: 17
Trainable params: 17
Non-trainable params: 0
_________________________________________________________________
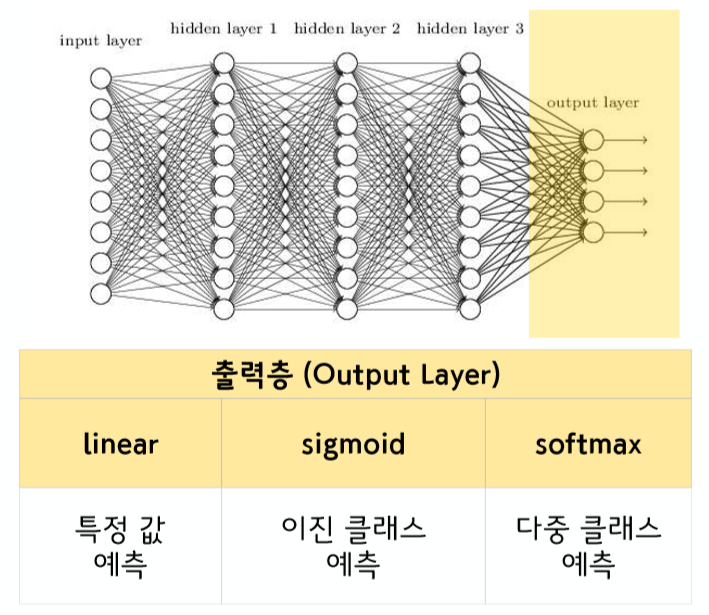
None출력층(Output Layer)
linear : 특정 값 예측
sigmoid : 이진 클래스 예측
softmax : 다중 클래스 예측
1 | # 5. Compile - Optimizer, Loss function 설정 |
WARNING: Logging before flag parsing goes to stderr.
W1123 21:54:23.066224 11320 deprecation.py:323] From c:\users\kyu93\appdata\local\programs\python\python37\lib\site-packages\tensorflow\python\ops\nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where1 | # 6. 학습시키기 |
Epoch 1/1000
4/4 [==============================] - 0s 1ms/step - loss: 0.3339 - accuracy: 1.0000
Epoch 2/1000
4/4 [==============================] - 0s 992us/step - loss: 0.3319 - accuracy: 1.0000
....
4/4 [==============================] - 0s 868us/step - loss: 0.0205 - accuracy: 1.0000
Epoch 999/1000
4/4 [==============================] - 0s 992us/step - loss: 0.0204 - accuracy: 1.0000
Epoch 1000/1000
4/4 [==============================] - 0s 858us/step - loss: 0.0204 - accuracy: 1.0000
<keras.callbacks.callbacks.History at 0x21a14b58748>1 | # 7. 모델 테스트하기 |
[[0.0208632]]2019.11.23. 딥-러닝 과정 Mulit Layer Perceptron(MLP)
세번째 실습. Keras 모델 생성/학습 - 당뇨병 예측 모델
1 | # 1. Pandas 가져오기 |
0.24.01 | # 2. 데이터 불러오기 |
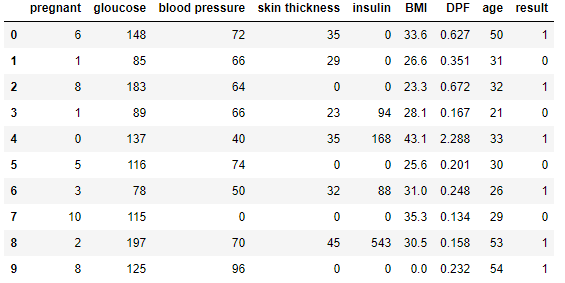
1 | # 3. X/y 나누기 |
(768, 8)
(768,)1 | # 4. Train set, Test set 나누기 |
(537, 8)
(537,)
(115, 8)
(115,)
(116, 8)
(116,)1 | # 5. Keras 패키지 가져오기 |
2.2.41 | # 6. MLP 모델 생성 |
WARNING:tensorflow:From /anaconda/envs/py35/lib/python3.5/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_7 (Dense) (None, 12) 108
_________________________________________________________________
dropout_1 (Dropout) (None, 12) 0
_________________________________________________________________
dense_8 (Dense) (None, 8) 104
_________________________________________________________________
dropout_2 (Dropout) (None, 8) 0
_________________________________________________________________
dense_9 (Dense) (None, 1) 9
=================================================================
Total params: 221
Trainable params: 221
Non-trainable params: 0
_________________________________________________________________
None1 | # 7. Compile - Optimizer, Loss function 설정 |
1 | # 8. 학습시키기 |
Train on 537 samples, validate on 115 samples
Epoch 1/1000
537/537 [==============================] - 1s 970us/step - loss: 4.9289 - acc: 0.5736 - val_loss: 3.2560 - val_acc: 0.6609
Epoch 2/1000
537/537 [==============================] - 0s 88us/step - loss: 3.4709 - acc: 0.6425 - val_loss: 3.2140 - val_acc: 0.6522
Epoch 3/1000
537/537 [==============================] - 0s 81us/step - loss: 3.7243 - acc: 0.5940 - val_loss: 3.0675 - val_acc: 0.6696
Epoch 4/1000
.......
537/537 [==============================] - 0s 91us/step - loss: 0.5624 - acc: 0.7207 - val_loss: 0.5805 - val_acc: 0.7304
Epoch 999/1000
537/537 [==============================] - 0s 97us/step - loss: 0.5566 - acc: 0.7169 - val_loss: 0.5870 - val_acc: 0.7391
Epoch 1000/1000
537/537 [==============================] - 0s 91us/step - loss: 0.5356 - acc: 0.7449 - val_loss: 0.5801 - val_acc: 0.73911 | # 9. 모델 평가하기 |
537/537 [==============================] - 0s 21us/step
116/116 [==============================] - 0s 27us/step
Train Acc: [0.5100221896970738, 0.7541899434681045]
Test Acc: [0.725729592915239, 0.6724137972141134]1 | # 10. 학습 시각화하기 |
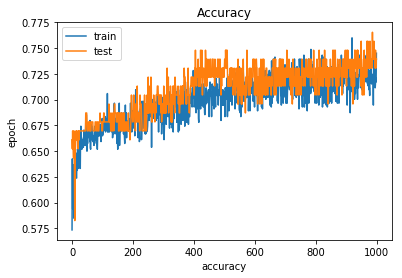
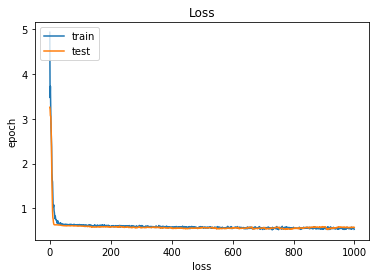
1 | ## 저장하기/불러오기 |
참조
https://ydseo.tistory.com/41
http://research.sualab.com/introduction/2017/10/10/what-is-deep-learning-1.html
https://blog.naver.com/minsu_jj/221607901559
https://hobbang143.blog.me/221469060596
https://gomguard.tistory.com/187